
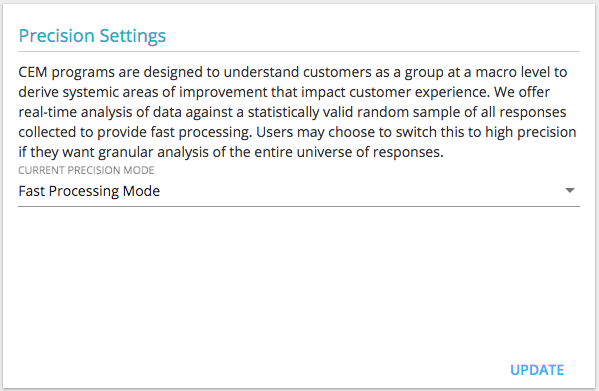
Precision Settings
Content Outline
High Precision Settings
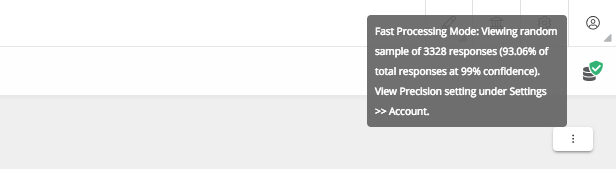
CEM programs are designed to understand customers as a group at a macro level to derive systemic areas of improvement that impact customer experience. We offer real-time analysis of data against a statistically valid random sample of all responses collected to provide fast processing.
Switching to High Precision
By default, this is set to fast processing. However, users interested in understanding the difference in the analysis may anytime choose to switch this to high precision if they want granular analysis of the entire universe of responses.
Follow these steps
- Click on the Profile icon
- Click on Edit Profile
- Scroll down to Precision Settings
- Switch Fast Processing to High Precision and hit Update.
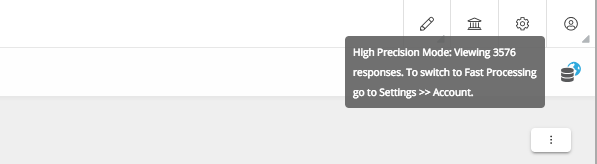
In High Precision mode, everything in the dashboard will be computed on the entire universe of all responses collected. Users can choose to switch back to fast processing anytime.
How Fast Processing Works
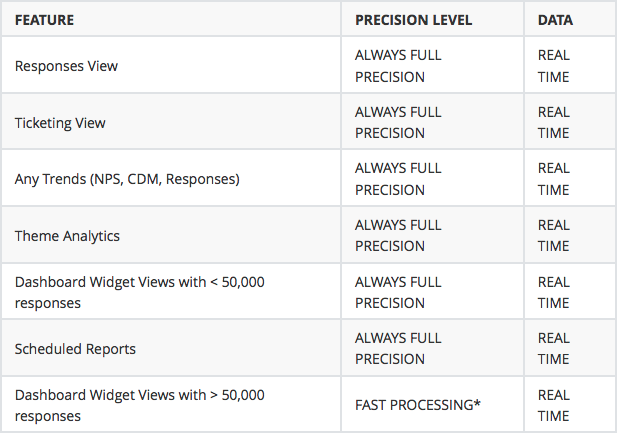
A CX program consists of two sets of data. Those that need to be read real time and those which are best suited to be read as a sample. Most Analytical outputs can be read on a sample selected using a robust random methodology and falling under a specific margin of error.
These are the data sets that would necessarily need to be read in real time across the entire universe
- NPS and NPS Trend - athough this is mathematically not required, because of Bain’s approach of reading comprehensive aggregate scores this is often preferred.
- Scores being used for Loop Closure necessarily need to be read in real time on the total universe
- Themes from open ended comments doesn’t have to be real time but needs to be read on the universe
All other data sets can be diagnosed on a sample, and is a very robust method of gathering insights rather than bundling all data together without context.
Sample sizes across Widgets
The sample size (count of responses) at different widgets may be different from the total count of responses (displayed in the Filter). This can be due to multiple reasons, and is independent of whether Fast Processing is turned on or not.

- The widget may be associated with optional questions, which some users may have chosen to skip.
- Different widgets may be associated with different questionnaires, which may be answered by different samples of users.
- The applied filters across questionnaires or cloned questions may impact the total count per widget.
- Data access permissions set up in enterprise roles and permissions may limit access for some users to some data sets.
- In cases where an experiment is being run, the control group and the variants may have been set up with different randomized sample sizes.
Robust Sampling Approach
- For the purpose analysis, we choose the sample only after definition of the context. For e.g.: if you want to analyze data for December - then we take the entire December universe and then identify a random sample within that
- If you are comparing across two data sets then we choose the random sample within the universe of each of those individual sets rather than choose a sample against an aggregate of the total set
- The sample size is determined to provide confidence levels of 99% on the selected universe
- For universe sizes less than 10,000 individual responses we don’t apply sampling
This approach uses rigor and an effective randomization methodology. The data doesn’t change if the user runs the same analysis multiple times on the same universe, similarly if two users are running the same analysis on the same universe the data arrived at will be identical.